



سیستم تشخیص گفتار(Speech Recognition)
تشخیص گفتار
تشخیص خودکار گفتار(Speech Recognition) که به فرایند تبدیل گفتار انسان به متن یا فرمان معادل گفته میشود، به رایانهها یا ماشینها این توانایی را میدهد که گفتار انسان را بشنوند و در مقابل آن واکنش مناسب نشان دهند. این مساله منجر به برقراری ارتباط سریع و آسان انسان با ماشینهای اطراف خود میشود و آنها را قادر میسازد تا بینیاز از دکمهها و کلیدها بتوانند با انواع رایانهها یا ابزارهای کاربردی روزمره خود به سادگی ارتباط برقرار نمایند.
یکی از مهمترین مزایای تکنولوژی تشخیص گفتار بهبود سطح رفاه و آسایش و تسهیل امور انسانها است. پردازش گفتار به عنوان یکی از زمینههای هوش مصنوعی به شبیهسازی مسائل مربوط به گفتاردرانسان شامل تشخیص و درک گفتار، تولید گفتار و بهبود کیفیت گفتار میپردازد. تشخیص خودکار گفتار یا بازشناسی گفتار، سنتز گفتار یا تبدیل متن به گفتار و غیره از جمله مهمترین زیرشاخههای پردازش گفتار میباشند که هرکدام نقش به سزایی در بهبود کیفیت زندگی افراد مختلف جامعه داشتهاند.
سیستمهای تشخیص گفتار چگونه عمل میکنند؟
رویکردهای مختلفی برای بازشناسی گفتار وجود دارد که موفقترین آنها رویکرد مبتنی بر تشخیص الگو است و تقریباً تمامی سیستمهای موفق امروزی بر اساس آن عمل میکنند. در این رویکرد گفتار به کمک تعدادی واحد آوایی (مانند کلمه ، هجا ، سه واجی یا واج ) مدل میشود و برای بازشناسی نیز از تشخیص این واحدها و کنار هم قرار دادن آنها، متن متناسب با گفتار تشخیص داده میشود. در شکل ۱ ساختار مرسوم برای یک سیستم بازشناسی گفتار (با رویکرد تشخیص الگو) نشان داده شده است.
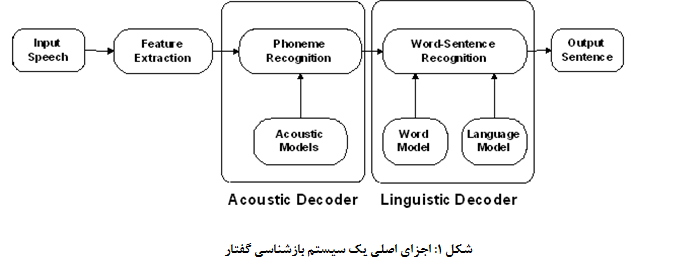
فاز آموزش و فاز آزمون
سیستمهای بازشناسی گفتاری که از این رویکرد استفاده میکنند، دارای دو فاز آموزش و آزمون میباشند. در فاز آموزش الگوهای مربوط به هرکلاس که همان واحدهای آوایی هستند، با استفاده از روشهایی مدلسازی میشوند. مقایسه گفتار ورودی با الگوهای آموزش داده شده جهت تشخیص واحدهای آوایی موجود درگفتار ورودی، در فاز آزمون انجام میگردد. همانگونه که در این شکل نشان داده شده است، یک سیستم بازشناسی گفتار شامل دو جزء اصلی استخراج ویژگیها و واحد مدل کردن ( برای فاز آموزش) و به کارگیری مدل یا جستجو (برای فاز آزمون) و استفاده میباشد. در این ساختار هر کدام از واحدهای مربوطه نیز خود به روشهای مختلفی قابل انجام هستند.
واحد استخراج ویژگی
واحد استخراج ویژگی که گاهی آن را پیشپردازش نیز میگویند، یکی از واحدهای مورد نیاز اغلب کاربردهای بازشناسی الگو میباشد. هدف این واحد در سیستمهای بازشناسی گفتار کاهش حجم محاسبات و حذف افزونگیهای موجود در سیگنال گفتار با استخراج تعداد محدودی پارامتر از آن است. پارامترهای استخراج شده توسط این واحد بایستی متناسب با کاربرد مورد نظر باشد. به این معنی که برای کاربرد بازشناسی گفتار مستقل از گوینده سعی شود پارامترهایی استخراج شود که حداقل حساسیت را به نحوه ادای آواهای مختلف یک گفتار خاص از نظر کلام و گوینده داشته باشند. از طرفی برای کاربردهای وابسته به گوینده مانند تشخیص هویت گوینده به کمک گفتار بهتر است واحد استخراج ویژگی پارامترهای وابسته به گوینده مانند وابستگی به لحن، شکل و طول مسیر صوتی ، طول گام و غیره را استخراج نماید.
از آنجا که کلیه عملیات بعدی روی این ویژگیها انجام میشود، بکارگیری یک روش توانا از عوامل موفقیت یک سیستم بازشناسی خواهد بود. با استفاده از روشهای استخراج ویژگی سیگنال به پارامترهایی که آنها را بردارویژگی مینامند تبدیل میشوند و کلاسهبندی روی این پارامترها صورت میگیرد. پارامترهای مورد استفاده عمدتاً از طیف کوتاه و پنجره بندی شده سیگنال گفتار که همان فریمها یا قابها هستند، بدست میآیند. روشهای مختلفی برای استخراج ویژگی وجود دارند که برخی از ایده تولید گفتار در سیستم صوتی انسان و برخی دیگر از ایده سیستم شنوایی بهره میگیرند. از میان روشهای مختلف برای استخراج ویژگی، دو روش آنالیز پیشگویی خطی (PLP) و ضرایب کپسترال فرکانسی در مقیاس مل (MFCC) به نسبت سایر روشها موفقتر و پرکاربردتر هستند.
در فاز آموزش معمولاً دو نوع مدل آماده میشود که در فاز آزمون از آنها استفاده شود، مدلهای آوایی و مدلهای زبانی . استخراج مدلهای آوایی از روی دادگان گفتاری و با استفاده از روشهای مختلفی امکانپذیر است . از مهمترین آنها میتوان روشهای مدل انطباق زمانی پویا یا DTW که در گوشیهای تلفن همراه برای شمارهگیری صوتی با بیان نام فرد به کار میرود، شبکه عصبی مصنوعی (ANN) و مدل مخفی مارکوف (HMM) را نام برد.
از میان این روشها، مدل مخفی مارکوف به نسبت سایرین موفقتر عمل کرده و عمده سیستمهای کاربردی امروزی از آن استفاده مینمایند. به علاوه ترکیب روشهای فوق نیز در برخی از سیستمها استفاده شده است. مدلهای زبانی معمول مورد استفاده در سیستمهای تشخیص گفتار امروزی شامل روشهای گرامری و آماری هستند.
روش های گرامی و آماری
در روش گرامری سعی میشود که به جملات خروجی ساختار گرامری آن زبان (یا آن کاربرد خاص) اعمال شود . و در روش آماری احتمال پشت سرهم آمدن کلمات (مثل مونوگرام یا احتمال وقوع کلمات در زبان، بایگرام یا آمار وقوع دو کلمه پشت سر هم در زبان و…) به عنوان مدلهای زبانی استخراج شده و مورد استفاده قرار میگیرند.
واژگان
واژگان نیز از اجزای اصلی مورد استفاده در سیستمهای بازشناسی گفتار هستند که شامل لیست کلماتی است که توسط سیستم بازشناسی میگردند. در واژگانهای مورد استفاده در سیستمهای بازشناسی گفتار پیوسته با تعداد واژگان زیاد، علاوه بر لیست خود کلمات، اطلاعات مختلفی در مورد هر کلمه مانند احتمال وقوع آن در زبان، احتمال وقوع آن بعد از سایر کلمات، نقش (های) گرامری در جمله و … را نیز شامل میشود. به این گونه واژگانها، واژگان محاسباتی گفته میشود.
جستجو
بعد از آموزش مدلها و هنگام آزمون یا استفاده، بایستی از روی ویژگیهای سیگنال، دنبالهای از آواهای مرتبط تشخیص داده شود و سپس باید برای دنباله آوایی پیدا شده بهترین دنباله کلمات مرتبط را پیدا کرد. به این فرایند جستجو گفته میشود. در یک سیستم بازشناسی گفتار پیوسته، با در اختیار داشتن مدلهای آکوستیک واحدهای آوایی، یافتن واحدهای آوایی گفتار ورودی به یک مسأله جستجو تبدیل میشود، به طوری که بهترین انطباق ممکن بین دنباله آوایی سیگنال ورودی و مدلهای آکوستیک ایجاد شود. در هنگام جستجو، احتمال تعلق یا میزان شباهت بردارهای ویژگی گفتار ورودی، با مدلهای مربوط به واحدهای آوایی، محاسبه شده و از میان محتملترین جوابها دنبالههایی از واحدهای آوایی به عنوان فرضیه شکل میگیرد. فرضیهای که بیشترین امتیاز را داشته باشد، بهترین جواب خواهد بود. در یک جستجوی کامل که همه فرضیههای ممکن مورد بررسی قرار میگیرند، تعداد فرضیهها با افزایش تعداد بردارهای ویژگی گفتار ورودی، به طور نمایی افزایش پیدا میکند، ار اینرو معمولاً از روشهای جستجویی استفاده میشود که قادرند به جای بررسی کل فضای جستجو، تنها با بررسی قسمتی از فضای جستجو، جواب خوبی بدهند. در بازشناسی گفتار پیوسته، روشهای مختلفی برای جستجو وجود دارد. مشهورترین روشهای جستجو عبارتند از: جستجوی ویتربی که بر مبنای الگوریتم ویتربی عمل میکند، جستجوی ویتربی شعاعی که شکل کاراتری از جستجوی ویتربی است و جستجو بر مبنای پشته که بر مبنای الگوریتم جستجوی *A عمل میکند.
در سیستمهای با واژگان بزرگ و سیستمهایی که واحد آوایی آنها واحدهایی کوچک مثل واج یا هجا هستند، بایستی دنباله آنها به دنباله کلمات تبدیل شود. از آنجایی که خروجی رمزگشای آکوستیک، دنبالهای ناقص و خطادار از واجها میباشد، برای تبدیل دنباله واجی به دنباله کلمات، نیاز به یک مدل زبانی و یک رمزگشای زبانی داریم. در تبدیل دنباله واجی به کلمات میتوان از دو رویکرد استفاده کرد. در حالت اول دنباله واجی حاصل از رمزگشای آکوستیکی به طور کامل تشکیل میشود، سپس با استفاده از درخت واژگان و الگوریتمهای جستجوی گراف، بهترین دنباله کلمات متناظر با دنباله واجی تشکیل میگردد. در رویکرد دوم، همزمان با شکلگیری دنباله واجی، بهترین دنباله کلمه نیز با جستجو در یک درخت واژگان به دست میآید. استفاده از اطلاعات بیشتر زبانی مانند اطلاعات آماری سطح بالاتر و استفاده از گرامر میتواند نتایج بهتری را منجر شود. این اطلاعات میتواند هم روی دنباله کلمات نهایی برای امتیاز دهی مجدد فرضیهها استفاده شود و هم در حین ایجاد دنباله کلمات از روی دنباله واجی جهت جلوگیری از رشد فرضیههای نادرست و ضعیف بکار گرفته شود. در آزمودن یک سیستم بازشناسی گفتار، ممکن است یکی از سه نوع خطای حذف ، درج و جایگزینی اتفاق بیافتد. خطای حذف زمانی اتفاق میافتد که یک واحد آوایی (کلمه یا واج) در سیگنال گفتار وجود دارد ولی بازشناسی نمیشود. درخطای درج، واحد آوایی بازشناسی شده در سیگنال گفتار وجود ندارد. این نوع خطا معمولا در هنگام تشخیص نویز به جای یک واحد آوایی پیش میآید. وقتی که یک واحد آوایی به اشتباه به جای یک واحد آوایی دیگری بازشناسی میشود، خطای جایگزینی رخ داده است. با توجه به این خطاها، برای ارزیابی عملکرد سیستمهای بازشناسی گفتار از چند معیار کارایی می توان استفاده کرد که دقت و یا به طور معادل نرخ خطای کلمات رایجترین آنهاست. دقت بازشناسی معادل درصد تعداد کلماتی (برای واحد آوایی کلمه) است که سیستم بازشناسی آنها به درستی تشخیص داده است.
مدل سازی آکوستیک : مدل مخفی مارکوف
- مدل مخفی مارکوف (HMM) رایج ترین مدل آکوستیک در بازشناسی گفتار می باشد.
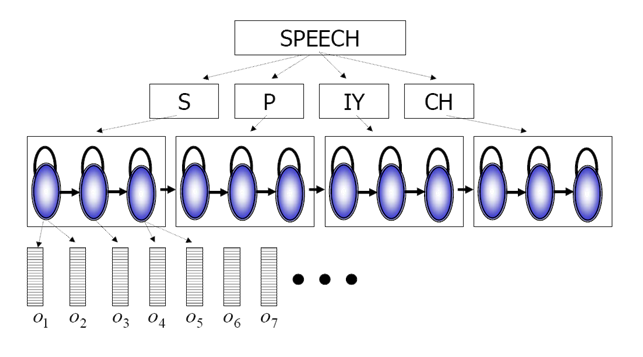
- حالات مختلفی که سیگنال گفتار در حین ادا شدن از آن عبور می کند را به عنوان state های HMMدر نظر میگیریم.
- در مدل سازی واجها معمولا برای هر HMM بین ۳ تا ۷ state در نظر گرفته میشود.
- در بازشناسی گفتار،stateها معولا دارای مشاهدات پیوسته در هر HMM میباشند.
- تابع چگالی احتمال مشاهدات در هر state معمولا به صورت توزیع گوسی در نظر گرفته میشود.
- پرش بین حالت ها معمولا به صورت چپ به راست در نظر گرفته میشود.
- احتمال وقوع بردار مشاهده (O= (O1,O2,…,Ok در حالت (s(state در HMM با چگالی پیوسته گوسی (با فرض مستقل بودن ابعاد بردار مشاهده) :
- با فرض وجود یک توزیع گوسی در هر state و با فرض مستقل بودن ابعاد بردار مشاهدات، هر state دارای یک بردار میانگین و یک بردار واریانس می باشد.
- پارامترهای HMM شامل ماتریس پرش بین stateها و بردارهای میانگین و واریانس توزیع گوسی در هر state میباشد.
مدل سازی آکوستیک: آموزش HMM ها
- در مرحله آموزش، پارامترهای HMM با استفاده از داده های آموزشی تخمین زده می شوند.
- با فرض داشتن تقطیع واجی در دادگان آموزشی، الگوریتم segmental K-means به صورت زیر برای HMM هر واج به کار می رود:
- برای سیگنال های گفتاری تمام واج ها در دادگان گفتاری استخراج ویژگی صورت می گیرد و دنباله ای از بردارهای ویژگی برای هر واج استخراج می گردد.
- به ازای هر یک از واج های زبان تمام دنباله بردارهای ویژگی آن در دادگان گفتاری جمع آوری می شود.
- دنباله بردارهای ویژگی بین state های HMM مربوط به آن واج به طور مساوی تقسیم می گردند.
- میانگین و واریانس بردارهای مربوط به هر state محاسبه شده و به عنوان پارامترای توزیع گوسی در آن state در نظر گرفته میشود.
- احتمال پرش بین stateها با استفاده از شمارش دنباله state منتسب به دنباله بردارهای ویژگی به دست میآید.
- به ازای هر نمونه از هر واج، یک الگوریتم ویتربی به ازای دنباله بردارهای ویژگی آن واج (دنباله مشاهدات) ودنباله state های HMM مربوط به آن واج اجرا می شود که در نتیجۀ آن بردارهای ویژگی به state های جدیدی منتسب می شوند.
- مراحل ۴ تا ۶ تکرار می شود تا زمانی که پارامترهای HMM به همگرایی برسند.
- در صورتی که دادگان آموزشی دارای تقطیع واجی نباشد، به ازای هر جمله ( utterance) در دادگان گفتاری،HMM های مربوط به واج های تشکیل دهنده آن به صورت زنجیروار به هم متصل شده و یک HMM بزرگ به وجود می آورند.
- الگوریتم segmental K-means با استفاده از این HMM های بزرگ انجام می گردد.
- مرحله decoding واج ها با استفاده از الگوریتم ویتربی انجام می شود.
Decoding
- مرحله decoding کلمات معمولاً با استفاده از یک درخت واژگان ( lexicon tree ) صورت می گیرد.
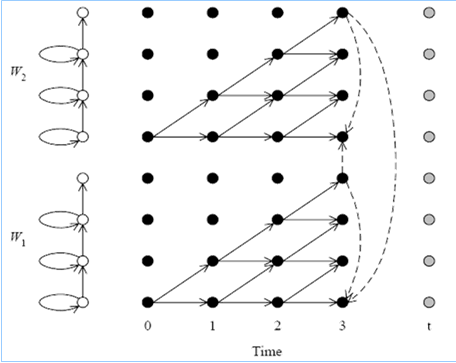
پس از شناسایی دنباله واج های گفتار، درخت واژگان بر اساس آن دنباله واج دنبال میشود و کلمات تشکیل دهنده دنباله واج ورودی به دست می آید.هنگامی که در درخت واژگان به یک گره نهایی می رسیم یک کلمه جدید تشکیل می شود وامتیاز مدل زبانی آن کلمه اعمال می گردد. دنباله واجی مربوط به هر فرضیه خروجی ممکن است دنباله کلمات متفاوتی تولید کنند وبدین ترتیب فرضیه های جدیدی تشکیل شودفرضیههای واجی که معادلی در درخت واژگان ندارند حذف می شوند. از بین N بهترین فرضیه خروجی، فرضیه ای که حاصلضرب امتیازهای آکوستیک و زبانی آن بیشتر باشد انتخاب به عنوان خروجی نهایی انتخاب می گردد.



با سلام
من یک voice recording دارم با کیفیت خیلی بد. میتوانید صدا را در این آنالیز کنید؟